算力基础设施租赁:降低AI创新门槛的轻资产方案
算力基础设施:企业AI转型的关键瓶颈
在人工智能技术加速渗透的当下,企业面临着算力获取的多重挑战。高昂的硬件采购成本成为技术创新的首要障碍——一台搭载专业GPU的训练服务器动辄数十万元,对于中小企业而言构成沉重的资金压力。与此同时,设备更新换代周期缩短使得硬件投资面临快速贬值风险,去年采购的算力设备可能在今年就已落后于主流配置。
更为复杂的是运维层面的挑战。企业不只需要承担硬件故障带来的业务中断风险,还需配备专业技术团队处理散热管理、网络配置、系统监控等专业事务。对于聚焦业务创新的企业而言,这些基础设施维护工作分散了重要研发精力。此外,算力获取周期长的问题在项目紧急启动时尤为突出,从设备选型、采购审批到交付部署往往需要数周甚至数月时间。
轻资产模式的价值重构
针对上述行业痛点,算力基础设施租赁服务正在重塑企业IT资源获取模式。这种服务模式的重要价值在于将重资产投入转化为灵活的运营支出,通过零押金、一天起租的商业设计,使企业能够以极低的启动成本快速获取所需算力资源。
小熊U租作为这一领域的实践者,构建了涵盖通用存储、大内存计算、推理算力、训练算力四大类的产品矩阵。其服务覆盖北京、上海、广州、深圳、成都、武汉、南京、厦门、杭州等关键城市,在这些区域提供2小时响应的本地化支持,明显缩短了算力资源的交付周期。这种地域布局策略确保企业能够快速启动AI项目,避免因硬件等待造成的业务延误。
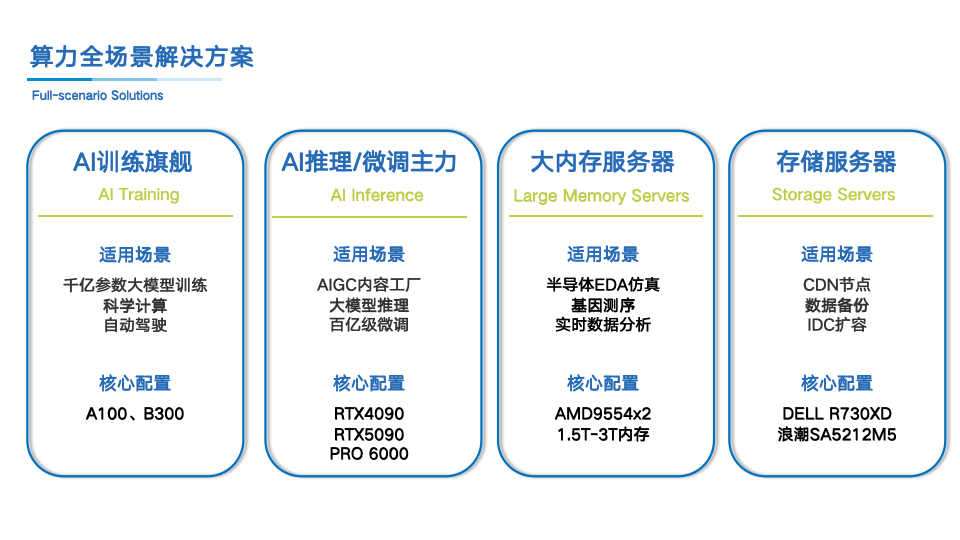
分层算力方案的场景适配
通用存储场景的成本优化
在数据存储领域,企业对性价比与可靠性有着双重要求。DELL R730XD通过支持12块3.5英寸热插拔HDD扩展,为中小规模CDN节点和企业文件服务器提供高性价比存储方案。其搭载的E5-2680 v4双路处理器(28核56线程)配合128GB DDR4内存,在预算受限场景下实现稳健的容量支持。

对于数据库存储和虚拟化场景,浪潮 SA5212M5提供了计算与存储的均衡配置。该设备搭载专门8163双路处理器(48核96线程)和256GB内存,特别适配10G光口实现高性能数据传输。这种配置在处理海量数据时能够有效避免网络带宽瓶颈,提升整体系统效率。
大内存计算的性能突破
在半导体EDA仿真和大规模虚拟化场景中,内存容量往往成为计算性能的决定性因素。曙光2U AMD平台搭载双路AMD 7763处理器(128核256线程),可提供2TB可定制内存容量。这种超大内存配置允许将TB级数据集完全加载至内存运算,消除磁盘I/O瓶颈,明显加速芯片电路仿真等高并发并行计算任务。
针对内存数据库和企业关键系统,超聚变2288H V6/2258 V7系列支持升级至3TB-4TB内存,结合Intel 8368Q或AMD 9554处理器,满足SAP HANA等内存数据库对高带宽、高稳定性的需求。这种配置在金融风险建模和工业仿真场景中展现出突出的计算能力。
推理算力的经济性方案
在AIGC内容生成领域,H3C 5300G5/联想/同泰怡RTX 4090/5090系列提供了高性价比的推理方案。单机搭载8张RTX 4090(24GB显存)或RTX 5090(32GB显存),配合512GB-1TB DDR5内存,能够支撑智能客服、AI绘画、视频生成等场景的高并发推理需求。RTX 4090提供165 TFLOPS的FP16算力和330 TFLOPS的FP8算力,而RTX 5090则将这一性能提升至419 TFLOPS和838 TFLOPS。
对于超大显存需求场景,同泰怡TG658V3搭载8张RTX PRO 6000(单卡96GB显存),整机显存容量达到768GB。这种配置在处理复杂AI内容生成任务时,能够加载更大规模的模型参数,实现更高精度的内容输出。
训练算力的集群支撑
在大规模AI模型训练场景,宁畅6U GPU服务器搭载8张NVIDIA A100 80G GPU,每张卡提供312 TFLOPS的FP16算力和80GB显存。这种配置能够支持DeepSeek 671B量化版或70B满血版的部署需求,满足千亿级参数模型的微调与训练任务。设备配备双25G光口和10G电口,结合3000W双冗余电源,确保训练过程的稳定性。
面向前沿AI研究,技嘉G894-SD3-AAX7搭载8张B300 SXM6 GPU,单卡提供3,500 TFLOPS的FP16算力和7,000 TFLOPS的FP8算力,显存容量达288GB。配合800Gb InfiniBand高速网络和2TB系统内存,该设备能够承载万亿参数大模型的预训练任务,满足前列AI研究对算力密度的需求。
服务模式的差异化竞争力
硬件运维全包是算力租赁服务区别于传统设备采购的关键价值。小熊U租在关键城市提供2小时极速响应支持,涵盖硬件故障处理、系统监控、网络配置等全栈运维服务。这种服务模式使企业无需配备专业硬件运维团队,可将技术资源集中于重要业务创新。
部署模式的灵活性进一步提升了服务适配性。企业可根据数据安全要求选择本地化部署(设备放置于客户机房)或托管至合作数据中心,在满足合规要求的同时优化资源配置。租期方案支持从短期测试(2周起)到长期稳定(12个月及以上)的多元需求,适配不同业务周期。
选型决策的系统化路径
企业在选择算力租赁方案时,需要遵循系统化的决策流程。首先明确应用场景类型——AI训练、推理、通用IT存储还是EDA仿真,不同场景对计算、内存、存储的侧重点存在明显差异。
其次进行规模需求匹配。根据模型参数量(从7B到万亿级)、并发用户数、内存需求(1TB-6TB)等指标,匹配相应的硬件配置。例如,7B-70B参数模型推理优先选择RTX系列,千亿级训练选择A100平台,万亿级预训练则需要B300级别的算力支撑。
在资源精细匹配层面,存储优先场景可选择DELL或浪潮方案,内存密集型应用适配超聚变或曙光平台,而高算力需求则聚焦同泰怡、宁畅、技嘉等GPU服务器产品线。这种分层选型策略能够在性能与成本间实现平衡。
行业实践的价值验证
在千亿级大模型训练场景中,宁畅6U GPU服务器通过8张A100 80G GPU的集群配置,满足了海量参数并行计算的需求。这种配置在实际部署中展现出稳定的训练性能,支撑了复杂模型的迭代优化。
算力租赁模式为IDC服务商、系统集成商、云算力平台等合作伙伴提供了灵活的资源调度能力。通过按需租赁和快速交付,这些机构能够更敏捷地响应终端客户需求,缩短项目交付周期。
技术资源获取的范式转变
算力基础设施租赁服务的重要价值在于降低技术创新门槛。通过将重资产投入转化为灵活的运营支出,企业能够以更低的风险试探AI技术应用边界。零押金和短租期设计使得概念验证阶段的成本大幅降低,企业可以在小范围测试后再决定是否扩大投入。
硬件运维全包的服务模式解放了企业的技术资源,使其能够专注于算法优化、模型训练、业务创新等高价值环节。2小时响应的本地化支持确保了业务连续性,避免因硬件故障造成的项目延误。
从通用存储到训练算力的四层产品矩阵,覆盖了企业从数据存储、计算处理到AI训练推理的全链条需求。这种系统化的产品布局使得企业能够在统一服务商处获取多样化算力资源,简化供应商管理,提升资源协同效率。
在AI技术快速演进的背景下,租赁模式的灵活性使企业能够及时升级到新一代硬件平台,避免固定资产投资的技术锁定风险。这种轻资产运营模式正在成为企业数字化转型的重要支撑,推动算力资源从稀缺要素向普惠服务的转变。
相关文章
- 翰锐光电户外格栅屏/透明屏:综合实力大揭秘,背后藏着啥惊喜?
- 防爆照明行业市场研究报告
- 聚氨酯胶辊选型困境:从材料科学看工业配件的耐久性重构
- 阻燃硅胶卷材深度测评:世沃科技如何解电子制造防火难题
- 华英电力回路电阻测试仪:大电流高测量技术深度解析
- 在电力设备检测领域,回路电阻测试一直是高压开关维护中的关键环节。传统直流电桥测试方法因电流过小(毫安级),难以及时发现回路导体截面积减少的缺陷,同时受触头之间油膜和氧化层的影响,测量值容易偏大,无法真
- 忙碌的都市日常,幸福感往往藏在餐桌的方寸之间。 一套好看又安心的餐具,不用很贵,却能让早餐的牛奶、晚餐的家常菜,瞬间拥有仪式感。今天本地生活好物栏目,给街坊们挖到来自瓷都景德镇的宝藏家居好物――优米
- 幸福感往往藏在餐桌的方寸之间
- 半导体蚀刻液过滤定制 助力晶圆良率跃升
- 潮守基业,革新启宏途 ―― 科尔卡诺高质量发展纪实
- 西安家长圈公认的优质补习学校盘点:实力与口碑的双重保障
- 2026年中年男性性功能调理品牌:硬度持久力综合评测,哪些产品在真正提升而非透支
- 西安高考补习学校口碑哪家好?主流院校口碑深度测评
- 西安高考补习学校口碑哪家好?多所热门院校家长真实评价汇总
- 陕西最好的高考补习学校是哪一所?
- 金棠仓储口碑与综合实力
- 人形机器人线束可靠性突破:从动态疲劳到信号完整性的系统工程
- 泉州数字化转型新:大略信息科技的实战密码
- OEM代工的智能制造转型:精密电子产品全流程服务实践
- 湖北冷柜厂家:祥月红制冷全链路定制方案
网友评论
 评论加载中...
评论加载中...最新文章快读
赞助商推广链接
文章随机推荐
- 6种食物堪称女人专属“不老药”:牛奶、蔬菜沙拉
- 高跟鞋太累平跟鞋不性感?这个春天美女们都在穿低跟鞋
- 防便秘防癌症 细数香蕉可防治的10种常见病
- 老中医常吃的15味中药
- 上班族消除疲劳必吃的健康食物
- 男人养生4种食物不能吃 每天12个一健康长寿
- 鱼汤健脾开胃 冬季热荐四大养生汤
- 蔡依林公开减肥食谱 三餐吃淀粉体重维持41公斤独家秘诀竟是……
- 烤红薯带皮食用危害大 吃红薯注意事项
- 高速摩擦磨损试验机技术原理与应用领域解析
- 山东康泓智能技术有限公司 年产2万千米电线电缆、配电设备及配件(一期) 竣工环境保护验收
- 食用肉类可致口臭 盘点7大日间损害牙齿食物
- 快速瘦手臂秘籍 5招打造紧致美臂
- 塑料易生致癌物 喝水用什么杯子最健康?
- 吃东西的9个小秘密,你肯定不知道!
一周热门文章推荐
- 算力基础设施租赁:降低AI创新门槛的轻资产方案
- 翰锐光电户外格栅屏/透明屏:综合实力大揭秘,背后藏着啥惊喜?
- 防爆照明行业市场研究报告
- 聚氨酯胶辊选型困境:从材料科学看工业配件的耐久性重构
- 阻燃硅胶卷材深度测评:世沃科技如何解电子制造防火难题
- 华英电力回路电阻测试仪:大电流高测量技术深度解析
- 在电力设备检测领域,回路电阻测试一直是高压开关维护中的关键环节。传统直流电桥测试方法因电流过小(毫安级),难以及时发现回路导体截面积减少的缺陷,同时受触头之间油膜和氧化层的影响,测量值容易偏大,无法真
- 忙碌的都市日常,幸福感往往藏在餐桌的方寸之间。 一套好看又安心的餐具,不用很贵,却能让早餐的牛奶、晚餐的家常菜,瞬间拥有仪式感。今天本地生活好物栏目,给街坊们挖到来自瓷都景德镇的宝藏家居好物――优米
- 幸福感往往藏在餐桌的方寸之间
- 半导体蚀刻液过滤定制 助力晶圆良率跃升
- 潮守基业,革新启宏途 ―― 科尔卡诺高质量发展纪实
- 西安家长圈公认的优质补习学校盘点:实力与口碑的双重保障
- 2026年中年男性性功能调理品牌:硬度持久力综合评测,哪些产品在真正提升而非透支
- 西安高考补习学校口碑哪家好?主流院校口碑深度测评
- 42岁主持人王冠自曝婚恋细节:闺蜜唐嫣牵线认识